
Dimensioneel modelleren met de BEAM*-modelstorming methode Om gedegen business intelligence producten te kunnen ontwikkelen voor organisaties, is het uiteraard van een erg groot belang om goed te begrijpen wat een organisatie precies doet en dit ook te vertalen naar een datamodel. De daadwerkelijke producten, diensten en bedrijfsprocessen dienen vertaald te worden naar dimensies, velden en tabellen die onderling relaties hebben.
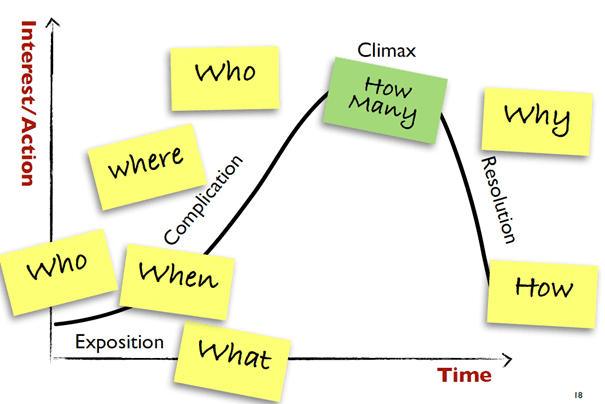
Dimensioneel modelleren met de BEAM*-modelstorming methode Om gedegen business intelligence producten te kunnen ontwikkelen voor organisaties, is het uiteraard van een erg groot belang om goed te begrijpen wat een organisatie precies doet en dit ook te vertalen naar een datamodel. De daadwerkelijke producten, diensten en bedrijfsprocessen dienen vertaald te worden naar dimensies, velden en tabellen die onderling relaties hebben. Met het opstellen van een dimensioneel model in een ster- of sneeuwvlokschema transformeer je een organisatie en haar processen naar een schematische weergave op basis waarvan BI ontwikkelaars dashboards kunnen ontsluiten. In deze vertaalslag zit echter een enorme uitdaging: de uiteindelijke BI ontwikkelaar zal de bedrijfsprocessen nooit zo goed kunnen doorgronden als de medewerker die deze operationele processen uitvoert en inhoudelijk expert is. Andersom spreekt een dergelijke medewerker meestal ook niet de technische taal van de BI-ontwikkelaar. Hoe voorkom je de reële mogelijkheid dat deze twee werelden langs elkaar heen praten waardoor het gewenste resultaat niet wordt bereikt met teleurstelling tot gevolg? Figuur 1: Voorbeeld van een dimensioneel model in de vorm van een sterschema Een goed geëquipeerde BI consultant heeft los van technische kennis ook de vaardigheid om bedrijven en hun processen snel te doorgronden. Meestal gebeurt dit door middel van business analyse en het voeren van gesprekken met medewerkers. Het opstellen van een dimensioneel model kan echter een stuk efficiënter en ook met meer plezier door gezamenlijke sessies te houden om een bedrijfsproces echt goed van A tot Z te doorgronden. De BEAM*-modelstorming methode, die is verzonnen door de Brit Lawrence Corr, is hier een uitstekende werkwijze voor. BEAM* staat voor B usiness E vent A nalysis & M odeling waarbij de * staat voor het uiteindelijke sterschema dat als eindresultaat uit deze werkwijze rolt. Bij deze methode verzamel je zo veel mogelijk betrokkenen van de relevante afdelingen in één ruimte en ga je een specifiek bedrijfsproces gezamenlijk volledig doorleven. Waarom het zo’n goed idee is om dit in een groepsvorm te doen toont de volgende korte en vermakelijke TED-talk erg duidelijk aan: De BEAM* methode gaat uit van een verhalende vorm van bedrijfsprocessen. In technische termen zou je een transactie heel feitelijk kunnen omschrijven als een uitwisseling van data tussen bijvoorbeeld twee applicaties. BEAM* werkt echter met ‘narratieven’ die ook herkenbaar zijn voor de operationele medewerkers. Wie doet Wat Wanneer Waar met Wie, Welke hoeveelheid en Waarom en Hoe gebeurt het (Who, When, What, Where, Who, hoW many, Why en hoW in het Engels)? Figuur 2: De 7 W’s op een chronologische schaal waarbij mate van importantie op de Y-as staat Stap 1: Het opstellen van een dergelijke flow voor een transactie met verschillende experts door middel van post-its en een muur is de eerste stap om scherp te formuleren wat voor velden en dimensies in het dimensionele datamodel moeten worden opgenomen. De verschillende W’s staan hier voor de uiteindelijke dimensies in het resulterende sterschema. Waarbij er voor één W ook verschillende dimensies kunnen bestaan: afhankelijk van hoe je je verhaal formuleert kan voor bijvoorbeeld ‘Wie’ zowel een dimensie ‘Klant’ als ‘Verkoper’ bestaan. In het centrum van het model staat ‘Welke hoeveelheid’ die de feitentabel van het bewuste proces representeert. Als format voor het brainstormen over de verschillende W’s is een BEAM-Canvas te gebruiken dat qua opmaak analoog is aan het bekende Business Canvas Model, waarmee bedrijven hun missie en visie kunnen definiëren. Bovenaan het model begin je met de vraag ‘Wie doet Wat’? Vanuit deze vorm is het namelijk natuurlijk om transacties verhalend te maken. ‘Klant bestelt product’ is een simpel voorbeeld hiervan. Voor iedere W kunnen vervolgens meerdere post-its op het canvas worden geplakt. Bij ‘Wie’ kunnen verschillende type klanten worden genoemd, bijvoorbeeld: resellers, retail klanten en B2B-klanten. Bij ‘Welke hoeveelheid’ kun je waardes definiëren als omzet in euro’s, volumes en winstmarges. Je vult het canvas meerdere keren voor de verschillende verhaallijnen die relevant zijn. Dus naast ‘Klant bestelt product’ kan dit ook zijn ‘Leverancier bezorgt product’. Figuur 3: Op het BEAM* Canvas worden door de groep post-its geplaatst om mogelijke waardes voor de verschillende W’s te identificeren. Stap 2: Als je het canvas hebt volgeplakt met de verschillende post-its die in het uiteindelijke datamodel staan voor de verschillende waardes die een dimensie kan hebben, kun je de verschillende opgestelde verhaallijnen op één tijdlijn plakken. Hierbij ontstaat het idee van de volgordelijkheid van de verschillende gebeurtenissen binnen één overkoepelend proces waardoor er meer structuur ontstaat. In deze stap ontstaan zeer nuttige discussies omdat vaak blijkt dat er over de exacte volgordelijkheid van processen binnen een organisatie vaak nog geen eenduidige consensus is. De gezamenlijke kennis van een groep medewerkers die inhoudelijke kennis van de relevante bedrijfsprocessen heeft is kortom superieur ten opzichte van de kennis die je als individuele BI consultant kunt opdoen op basis van business analyse en interviews. Je maakt gebruik van de ‘wisdom of the crowd’ en dit levert vrijwel altijd betere resultaten op. Ook kun je met deze werkwijze de betrokkenheid van medewerkers bij de toekomstige BI-oplossingen vergroten aangezien ze zelf een daadwerkelijke bijdrage hebben geleverd aan de technische oplossing die ze uiteindelijk zelf mogelijk ook gaan gebruiken. Wat maakt de BEAM* methode zo een goede techniek om gezamenlijk tot een gedegen datamodel te komen? Figuur 4: de verschillende waardes uit het BEAM* canvas worden op een tijdlijn geplakt om de chronologie te bepalen Het is hierbij ook belangrijk om te bepalen over wat voor verhaaltype het gaat met betrekking tot de tijdlijn. Betreft het een proces met simpele eenmalige transacties, zoals de fysieke aankoop van producten in een winkel? Of betreft het een proces waarbij het start- en eindpunt verder uit elkaar liggen op de tijdlijn in bijvoorbeeld een online bestelling die ook nog verscheept moet worden uit China en langs verschillende distributiecentra gaat? Figuur 5: Verschillende types tijdlijnen behorend bij verschillende types transacties Stap 3: Na het uitkristalliseren van de tijdlijn wordt een ‘event matrix’ samengesteld waarbij terugkerende ‘zelfstandig naamwoorden’ worden geïdentificeerd en op de horizontale as worden geplaatst. Deze zelfstandig naamwoorden staan voor de verschillende entiteiten binnen de dimensies van het aanstaande sterschema, zoals bijvoorbeeld ‘Product’, ‘Klant’ en ‘Promotie’. De ‘werkwoorden’, die staan voor gebeurtenissen en die in het sterschema in de feitentabel worden opgenomen, worden op de verticale as geplaatst. In de feitentabel van een sterschema staan de daadwerkelijke transacties met een datummarkering en kwantiteit (in volume, omzet, winst etc.). Het is te verwachten dat bijvoorbeeld de entiteit ‘Product’ op veel verschillende momenten op de tijdlijn relevant is. Een product is namelijk onderdeel van verschillende verhaallijnen: de fabriek maakt het product, de leverancier verplaatst het product, de verkoper verkoopt het product aan de klant. Door deze opgestelde matrix is dus snel visueel vast te stellen wat de belangrijkste dimensies en velden zijn in het uiteindelijke datamodel. Tevens kun je met specifieke symbolen aangeven of een entiteit door de betreffende transactie ontstaat. Door de verhalende transactie (op de Y-as) ‘Klant bestelt Product’ ontstaat bijvoorbeeld de entiteit ‘Bestelnummer’. Deze verfijning geeft een extra visuele kracht aan de event matrix. Figuur 6: De BEAM* event matrix waarop snel belangrijke entiteiten binnen een proces zijn te identificeren en markeren. Stap 4: Hierna kan deze event matrix worden vertaald naar het BEAM storyboard. Door het opstellen van dit storyboard ontstaat er wederom een logisch chronologisch proces waaruit nu ook de belangrijkste entiteiten te herkennen zijn aan de mate waarin ze in de verschillende verhaallijnen voorkomen. Figuur 7: Het BEAM-storyboard. De verschillende verhaallijnen met bijbehorende entiteiten en gebeurtenissen worden op één chronologische weergave geplot De verhalende transacties worden hierbij in een chronologische volgorde geplaatst op de X-as waarna op de Y-as al de entiteiten worden geplakt die betrokken zijn bij deze transacties. Hierbij wordt dus het werk van de vorige stappen gecombineerd op een groot totaaloverzicht en hiermee heb je het hele overkoepelende bedrijfsproces met verschillende verhaallijnen zowel chronologisch als inhoudelijk opgesteld in samenwerking met een groep betrokkenen. Figuur 8: Voorbeeld van een deels gevuld BEAM-storyboard Stap 5: Nu het gehele bedrijfsproces op deze manier inzichtelijk is gemaakt kunnen de losse post-its die staan voor verschillende entiteiten verder worden uitgediept in de BEAM table. In deze tabel wordt gebrainstormd over de mogelijke waardes die onder iedere entiteit kunnen vallen en wat de mogelijke regels in een resulterende datamart zouden kunnen zijn. Waar het opstellen van deze tabel enorm bij helpt is het bepalen van uitzonderingen en veelvoorkomende waardes. Is het in bepaalde gevallen bijvoorbeeld mogelijk dat een waarde ontbreekt, bijvoorbeeld als de klant onbekend is? Wat is de oudst mogelijke transactie die inzichtelijk moet zijn, kortom wat zijn de vereisten aan het model met betrekking tot historische opslag van data? Zitten er patronen in bepaalde transacties, zoals een periodieke herhaling? Het op deze wijze vullen van de tabel geeft zodoenede nog heel veel extra detailinformatie die ook uitermate nuttig is voor het technisch uitwerken van het datamodel. Het bepaalt als het ware de kaders waarbinnen het datamodel binnen de verschillende dimensies opereert. Figuur 9: De BEAM-table helpt bij het visualiseren van de uiteindelijke regels in een resulterende datamart en bepaalt de kaders van en de vereisten aan het datamodel Stap 6: Na het doorlopen van al deze stappen heb je als business analist genoeg informatie om aan de slag te gaan met het opstellen van het datamodel in de vorm van een sterschema. De plaatsing van de dimensies rondom de centrale feitentabel kan qua opbouw analoog aan hoe in stap één het BEAM* canvas is gevuld. elementum elementum. Nec sapien convallis vulputate rhoncus vel dui. Figuur 10: Het resulterende sterschema kan qua dimensies analoog worden opgebouwd aan het BEAM-canvas uit stap één. Zo is de cirkel weer rond. Het op deze wijze opstellen van een dimensioneel model leidt tot betere resultaten omdat je de aanwezige kennis binnen een organisatie in een gezamenlijke sessie optimaal gebruikt. Daarnaast vergroot deze aanpak de betrokkenheid van medewerkers bij zowel de uiteindelijk BI-oplossing, alsook de onderlinge betrokkenheid omdat verschillende afdelingen samenwerken om een bedrijfsproces volledig van A tot Z uit werken. Naast de vele praktische voordelen van werken met BEAM*-modelstorming is het op deze manier opstellen van een datamodel ook gewoon erg leuk en komt er in dit soort groepsessies altijd veel positieve energie vrij. Mocht u geïnteresseerd zijn in werken met het BEAM*-modelstorming, schroom dan niet om contact met ons op te nemen: Pjotr PostmaBI consultant

