Dit blog is geschreven naar aanleiding van een succesvolle ervaring bij een van onze klanten, waarbij ongeveer 55 miljoen records succesvol zijn gemigreerd.
Online is al veel informatie te vinden over het migreren van gegevens in OutSystems. Natuurlijk zijn er diverse benaderingen om dit aan te pakken. Degenen met enige expertise weten we dat de tabellen die zichtbaar zijn in Service Studio niet direct overeenkomen met de feitelijke tabellen. Onderliggend verwijzen deze tabellen naar ‘physical tables’, die zich bevinden in een SQL-serverdatabase. Op het moment dat je een tabel wil kopiëren naar een andere module wordt er onder water een nieuwe ’pshysical table’ aangemaakt. Dit betekent dat er dus geen tabellen inclusief data kunnen worden verplaatst binnen Service Studio (uitgezonderd Static Entities).
Out Of The Box heeft OutSystems geen tool om een data migratie uit te voeren. In de OutSystems Forge zijn er componenten beschikbaar, maar ook deze voldoen niet altijd aan de wensen. Daarnaast wil je bij een data migratie volledig in control zijn over welke tabellen én data je wil migreren. Hoe doe je dit? Door het migratiescript zelf te ontwikkelen in OutSystems. Gedurende de migratieperiode zijn we een aantal obstakels tegengekomen. Deze worden uitgelicht in de ‘lessons learned’.
In dit artikel laten we je zien hoe we data hebben verhuisd binnen het OutSystems-platform. We nemen je mee door de stappen die we genomen hebben om ervoor te zorgen dat de gegevens na de verhuizing volledig betrouwbaar waren.
Situatie
De applicatie is opgezet als een monolith applicatie waarbij minder aandacht is besteed aan de best practices die OutSystems hanteert op het gebied van architectuur. Deze manier van opzet bood, toen het nog een kleine applicatie was, een snelle en vooral eenvoudige time-to-production. In de loop der tijd is de applicatie gegroeid en volstond de huidige opzet niet meer. De nieuwe opzet van de applicatie zorgde ervoor dat het datamodel over meerdere applicaties heen verspreid zou worden.
HUIDIG DATAMODEL (IST)
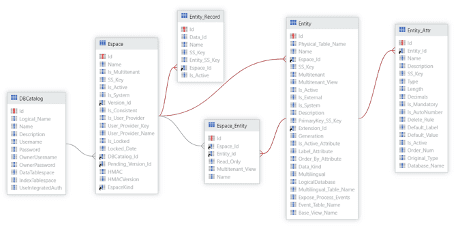
In de eerste fase van dit traject is eerst het bestaande datamodel in kaart gebracht. Het in kaart brengen van dit model is een belangrijke stap om een succesvolle en gestructureerde migratie te garanderen, waarbij risico’s worden verminderd en de gegevensintegriteit wordt behouden. Er zitten enkele voordelen aan verbonden.
Betere planning: Door het bestaande datamodel te begrijpen, kun je een gedegen plan opstellen voor de migratie.
Dit omvat het vaststellen van de onderlinge afhankelijkheden tussen diverse gegevenselementen en het bepalen van de meest geschikte volgorde voor migratie. Een grondig overzicht helpt bij het inschatten van de benodigde tijd en middelen, en minimaliseert mogelijke verstoringen.
Risicoanalyse: Het in kaart brengen van het datamodel helpt bij het opsporen van mogelijke risico’s en uitdagingen die tijdens de migratie kunnen optreden. Het identificeren van deze risico’s zorgt ervoor dat we op voorhand maatregelen kunnen nemen.
Mapping van gegevens: Door het huidige en nieuwe datamodel te visualiseren wordt het mappen van gegevens eenvoudiger. Dit is uiteindelijk van cruciaal belang om ervoor te zorgen dat de processen na de migratie soepel blijven verlopen.
Gewenst datamodel (SOLL)
Het opstellen van een gewenst datamodel helpt bij het bepalen van de richting van de migratie, het stroomlijnen van bedrijfsprocessen en het waarborgen van een effectieve en geoptimaliseerde gegevensstructuur na de migratie. Een greep uit de voordelen;
Gerichte migratie: Door een duidelijk gewenst datamodel te definiëren, kunnen heldere doelstellingen voor de migratie worden vastgesteld. Dit stelt het team in staat om doelgericht en efficiënt te werken, met een specifieke visie op het gewenste resultaat.
Structuur optimalisatie: Door het gewenste datamodel van tevoren te bepalen, kunnen optimalisaties in de gegevensstructuur worden geïdentificeerd en toegepast. Dit kan leiden tot verbeteringen in prestaties, efficiëntie en beheerbaarheid na de migratie.
Verbeterde datakwaliteit: Door van tevoren aandacht te besteden aan het gewenste datamodel, kunnen eventuele problemen met datakwaliteit worden geïdentificeerd en aangepakt tijdens de migratie. Dit resulteert in een verbeterde algehele kwaliteit van de gegevens.
Eenvoudiger beheer en onderhoud: Een vooraf gedefinieerd datamodel vereenvoudigt het beheer en onderhoud van de gegevensstructuur na de migratie. Het maakt aanpassingen en updates makkelijker te implementeren en draagt bij aan een duurzaam beheer van gegevens.
Het migratiescript
Het migratiescript bestaat uit verschillende onderdelen:
- Migratietabel;
- Conversiescript;
- Rollbackscript;
- MigratieRun-Logica.
Migratietabel
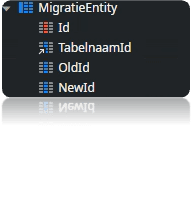
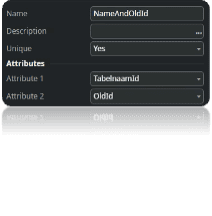
Een migratietabel is een ondersteunende tabel die zorgt voor de mapping van oude Foreign Keys naar nieuwe Foreign Keys. Deze tabel heeft een relatie met ‘Tabelnaam’, waarin de namen van de tabellen worden opgeslagen die worden gemigreerd. Dankzij de relatie met ‘Tabelnaam’ is het in het conversiescript mogelijk om met de migratie-entiteit te communiceren en de bijbehorende oude en nieuwe Identifiers op te halen.
Bij het aanmaken van deze ’MigratieEntity’ tabel dient er rekening gehouden te worden met indexen. Indexen versnellen het zoekproces in een database. Ze dienen als een geoptimaliseerde route naar de specifieke rijen die aan de zoekcriteria voldoen, waardoor de zoekopdrachten sneller worden uitgevoerd.
Door de oude en nieuwe foreign key-relaties te koppelen via een migratietabel, kun je de integriteit van de gegevens waarborgen gedurende het migratieproces. Hierdoor wordt voorkomen dat er inconsistente gegevens ontstaan tijdens het proces.
Conversiescript
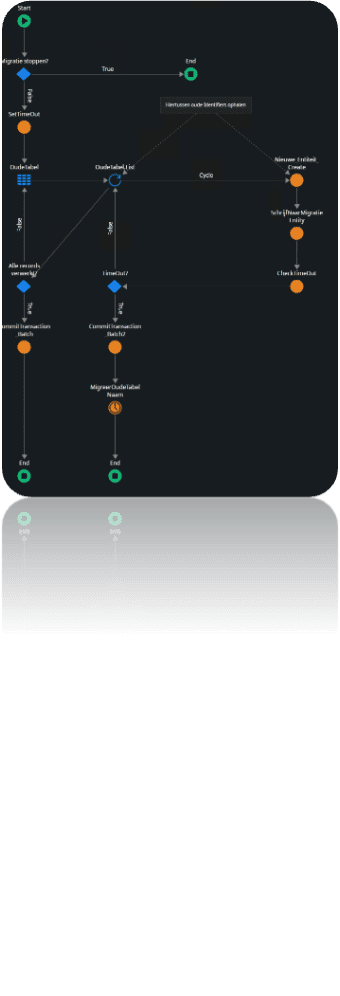
Het conversiescript (zie afbeelding rechts) vormt de kern van de migratie. Tijdens deze procedure wordt het volgende uitgevoerd:
- De oude tabel wordt geraadpleegd.
- Er zit een cap op het aantal records dat opgehaald wordt
- Er wordt gecontroleerd of deze tabel al is gemigreerd.
- Dit gebeurt door middel van een left outer join tussen {OudeTabel} en {MigratieEntitiy} op {MigratieEntity}.[OldId] = {NieuweTabel}.[Id]] en een filter met {MigratieEntity}.[Id] = NullIdentifier()
- Een nieuw record wordt aangemaakt in de nieuwe tabel.
- Een update wordt uitgevoerd op de {MigratieEntity}.
- De NewId wordt gevuld met de identifier van het zojuist gecreëerde record.
Er wordt rekening gehouden met TimeOuts door middel van een TimeOut Controller en alle verwerkte records worden gecommit.
Door vooraf het beoogde datamodel gedegen in kaart te brengen, ontstaat helderheid over de hiërarchie van relaties. Hierdoor wordt duidelijk welke onderliggende tabellen opgehaald dienen te worden om de nieuwe foreign keys te kunnen toewijzen.
Rollbackscript
Een migratie rollback script is noodzakelijk om een terugdraaimogelijkheid te bieden in het geval er problemen optreden tijdens het migratieproces.
Tijdens de migratie kunnen er onvoorziene problemen optreden, zoals datacorruptie, fouten in het script of andere technische complicaties. Een rollback script stelt je in staat om de wijzigingen onmiddellijk en gecontroleerd terug te draaien als er zich een probleem voordoet.
Migratierun Logica
Het MigratieRun-script fungeert als de verzameling van alle conversiescripts, waarbij deze operationele logica wordt ondersteund door een specifieke tabel genaamd {MigratieStap}. Deze tabel registreert op welke specifieke stap het algehele migratiescript zich bevindt. In situaties waarin zich fouten voordoen of time-outs plaatsvinden, verschaft deze tabel het script de nodige informatie om te bepalen op welk punt het migratieproces opnieuw moet worden geïnitieerd. Deze doelbewuste benadering verzekert een gecontroleerde en gestructureerde uitvoering van het migratieproces, waarbij adequate herstelmaatregelen worden geboden om eventuele onregelmatigheden effectief aan te pakken en een naadloze voortgang van het migratieproces te waarborgen.
Lessons learned
- Aantal op te halen records vergroten
- Het aantal op te halen records (Max. Records) vanuit de ‘OudeTabel’ is vergroot. Het in één keer fetchen van deze data ging sneller dan het tien keer fetchen van kleine batches.
- Bulkinserts
- Het toevoegen van BulkInserts zorgde voor een versnelling van het datamigratie proces.
STATISTIEKEN

Jorick van Rijs
OutSystems Consultant @ Conspect