In een wereld waarin steeds grotere volumes aan data rondgaan zoeken organisaties naar betere en moderne manieren om hun data zo goed mogelijk te gebruiken.
Databricks is een relatief jonge speler die daarin erg in opmars is, zo ook in mijn vakgebied als Data-Engineer. Databricks staat bekend als een data-platform dat de kracht van big data-analyse en machine learning combineert, maar is veel breder inzetbaar voor organisaties dan dat. Of je nu een Data Engineer, Data Scientist, of een zakelijke gebruiker bent, Databricks biedt een diversiteit mogelijkheden om waardevolle inzichten te verkrijgen op een moderne en gebruiksvriendelijke manier. In deze blog gaan we het hoog-over hebben wat databricks kan vanuit het perspectief van een Data-Engineer, maar schetsen hierbij ook de strategische voordelen en uitdagingen.
Wat maakt Databricks zo uniek en waarom noem ik het de (bijna) alleskunner?
In deze blog duiken we hoog-over in de mogelijkheden van Databricks en laten we zien hoe het platform niet alleen met een frisse blikt kijkt naar het werken met data, maar ook direct bijdraagt aan zakelijke groei en innovatie.
Van het verwerken en analyseren van enorme datasets tot het trainen van complexe machine-learning modellen en het stroomlijnen van ETL-processen – Databricks doet het allemaal.
Een Korte geschiedenis en achtergrond van Databricks
Databricks werd in 2013 opgericht door de originele ontwikkelaars van Apache Spark, een open-source big data verwerkingsengine. Het doel hiervan was om een platform te creëren dat de kracht van Apache Spark toegankelijk maakt voor bedrijven en organisaties, waardoor ze complexe data-analyse en machine learning taken kunnen uitvoeren op schaal.
Deze schaalbaarheid was, ten tijde van de opkomst van de eerste cloud tooling zoals Azure, erg interessant voor grotere organisaties met grote data-volumes. Sindsdien is Databricks uitgegroeid tot een toonaangevend data-analyse platform dat wereldwijd door tal van bedrijven wordt gebruikt om data om te zetten in waardevolle inzichten. Verder verenigt het verschillende rollen die met data werken in één platform.
Hoe Werkt Het Platform?
Databricks biedt een geïntegreerde omgeving waarin Data Engineers, Data Scientists en Analisten naadloos kunnen samenwerken aan data-verwerking, analyse en modellering. Het platform draait op Apache Spark Clusters en ondersteunt een breed scala aan programmeertalen zoals Python, R, Scala en SQL. Hierdoor kunnen ontwikkelaars met verschillende achtergronden snel aan de slag met hun dataprojecten. Gebruikers hebben de mogelijkheid om notebooks, workflows, jobs en dashboards te creëren voor het inzichtelijk maken van stuurinformatie. Bovendien is Databricks zonder vendor-lock beschikbaar op de Cloudplatformen van Azure, Amazon en Google, wat het een flexibel onderdeel maakt van elke Cloudomgeving. Een voorbeeld van Databricks in een Azure-architectuur wordt hieronder gepresenteerd. Verderop in deze blog wordt ook de medallion architectuur besproken, die beschrijft hoe data binnen Databricks wordt opgeslagen en beheerd.
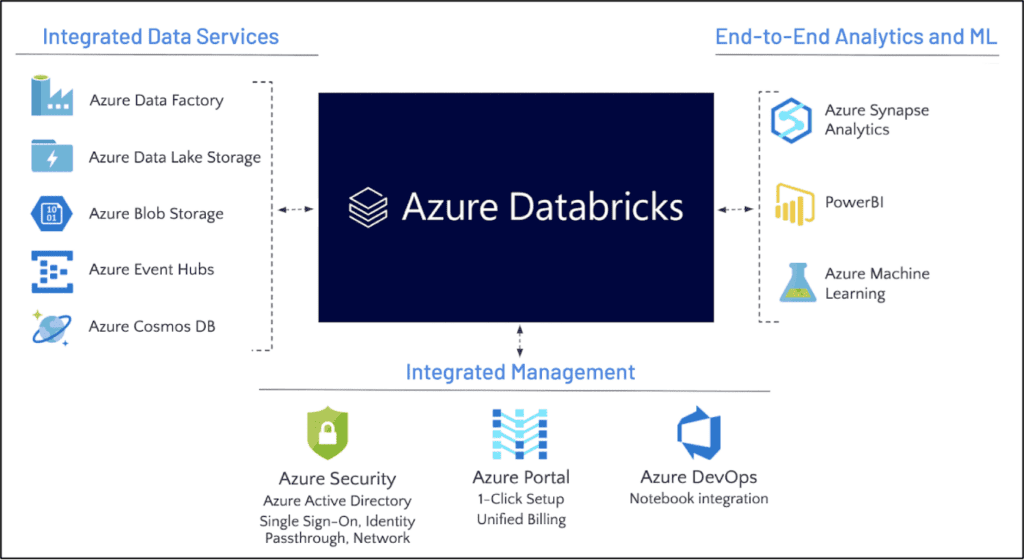
Welke onderdelen zijn er in Databricks?
Het maken en verladen van data gaat middels verschillende componenten in Databricks, in de onderstaande alinea’s zullen we deze kort toelichten.
Notebooks
Notebooks zijn blokken waarin een ontwikkelaar Python, SQL, Scala of R code naar wens in verschillende stappen kan verwerken. De gemaakte code kan dan stapsgewijs worden uitgevoerd, wat helpt bij het debuggen en het iteratief ontwikkelen van data pipelines. Als eindresultaat kunnen we bijvoorbeeld een dataframe wegschrijven naar een storage account in Azure en daarmee naar onze delta table. We kunnen tussentijds ook middels bijvoorbeeld SQL, Delta tables querien of tussentijds het resultaat bekijken van onze weggeschreven data. Een van de zaken die mij goed is bevallen, is de mogelijkheid om tussen de codeblokken ook markdown cellen toe te voegen met uitleg over de geschreven code, of tekstuele plaatjes over de koppeling tussen verschillende datasets. Mijn persoonlijke ervaring is dat dit prettig werkt en dat je je dataset stap voor stap kan opbouwen doormiddel van verschillende dataframes en zo transformaties kan doen over de verschillende dataframes of SQL query’s. Het werkt ook prettig dat je in één notebook meerdere soorten code kan gebruiken, bijvoorbeeld één codeblok in Python en een deel in SQL. Een ander stuk functionaliteit binnen notebooks is dat je deze kan delen met andere ontwikkelaars en een changelog hebt op bestandsniveau, waardoor je snel en overzichtelijk alle wijzigingen gedaan door collega’s kan zien en doelgericht kan sparren over de code. Verder kan je ook in real-time samen werken binnen notebooks, zoals in office365 producten, je ziet dan live de code die je collega typt verschijnen en waar zijn of haar cursor staat binnen het notebook.
Tot slot ondersteunt Databricks integratie met verschillende versiebeheertools zoals Git, wat samenwerking verder vergemakkelijkt, code veiligstelt en de mogelijkheid biedt om met CI/CD pipelines te werken.
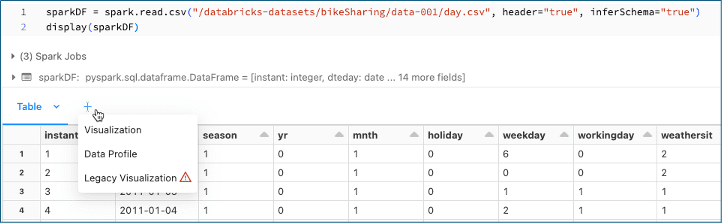
Jobs
In Databricks kunnen jobs worden aangemaakt om notebooks automatisch volgens een vast schema uit te voeren, bijvoorbeeld om data dagelijks bij te laden. Hoewel er vaak andere tools zoals Azure Synapse of Apache Airflow worden ingezet voor orkestratie, biedt Databricks met Workflows nu ook een ingebouwde optie om jobs direct binnen het platform te beheren. Dit maakt het mogelijk om alles, van het ontwikkelen van code tot het dagelijks plannen en uitvoeren ervan, binnen één omgeving te doen, zonder dat een externe orkestratietool nodig is. De jobs zijn bovendien flexibel en kunnen eenvoudig worden geparametriseerd, zodat ze bijvoorbeeld dagelijks, maandelijks of op specifieke dagen worden uitgevoerd. Of je nu Workflows, Airflow of Synapse gebruikt, de processen blijven overzichtelijk in Databricks omdat het Databricks-cluster zelf wordt ingezet. Dit zorgt ervoor dat je in één tool inzicht hebt in welke processen zijn bijgewerkt en doorgeladen.
Dashboards
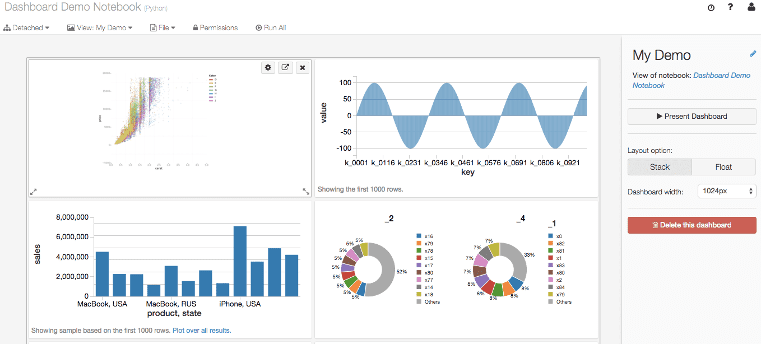
Een van de handige features van Databricks zijn de Dashboards. Met Dashboards kunnen gebruikers middels Visuals inzichten presenteren die rechtstreeks uit hun data-analyses voortkomen. Deze dashboards zijn ideaal voor het delen van belangrijke informatie met stakeholders die mogelijk geen technische achtergrond hebben maar wel behoefte hebben aan toegang tot up-to-date data en inzichten.
Dashboards kunnen worden gemaakt vanuit notebooks, waarbij de visualisaties die in de notebook zijn gegenereerd eenvoudig kunnen worden toegevoegd aan een dashboard. Dit geef weer de mogelijkheid om complexe data-analyses te vertalen naar visuele rapportages. Gebruikers kunnen verschillende soorten grafieken en tabellen toevoegen aan hun dashboards, zoals lijndiagrammen, staafdiagrammen en draaitabellen, afhankelijk van wat het beste de gegevens weergeeft.
Een bijkomend voordeel is dat deze Dashboards real-time geüpdate kunnen worden. Dit betekent dat zodra de onderliggende data verandert, de visualisaties in het dashboard automatisch worden bijgewerkt. Hierdoor hebben gebruikers altijd toegang tot de meest actuele informatie. Bovendien kunnen dashboards worden gedeeld met andere teamleden of afdelingen binnen de organisatie, waardoor samenwerking en data-gebaseerde besluitvorming worden bevorderd.
Bovenstaande zaken zoals real-time update zijn ook mogelijk in Powerbi maar dan zijn er extra stappen voor nodig omdat dit niet geïntegreerd is met Databricks zoals Databricks Dashboards. Met de integratie van verschillende datastromen in één overzichtelijk platform, biedt Databricks Dashboards een handige manier om inzichten te visualiseren en te communiceren.
Dit geldt zowel voor bijvoorbeeld het volgen van de prestaties van een Machine Learning model als het monitoren van ELT-processen, of het presenteren van key performance indicators (KPI’s) aan het management.
Dashboards in Databricks maken het eenvoudig om data om te zetten in actiegerichte informatie. Ook binnen Databricks kunnen eindgebruikers filteren en sorteren zoals gewend in tools zoals Powerbi en tableau qua functionaliteit is dit redelijk gelijkwaardig.
De ervaring leert wel dat momenteel nog vaak Powerbi de meest populaire tool is qua reporting maar Databricks biedt een kleinschalige oplossing waarmee je snel aan de slag kan en binnen databricks als tool kan functioneren zonder extra licenties. Na vergelijk van beide tools kunnen we wel concluderen dat Powerbi een gebruiksvriendelijkere optie is voor eindgebruikers vanuit de business.
Hoe worden zaken als notebooks en jobs dan gerund?
Aangezien Databricks een cloud-tool is maken we gebruik van clusters, een cluster is een groep virtuele machines die samenwerken om je data-verwerkings taken uit te voeren.
Zo’n cluster wordt aangestuurd door een zogenaamde driver node, die als een coördinator de worker nodes aansturen welke het rekenwerk uitvoeren.
Deze clusters draaien weer in de cloudinfrastructuur van de cloudproviders zoals Microsoft/Azure/Google. In dit geval levert Databricks het platform om deze resources te beheren en te gebruiken.
Wat zijn de use-cases van Databricks:
Databricks staat primair het meest bekend staat als een platform voor Big-Data analyse en Machinelearning is dit door de jaren continue uitgebreid qua functionaliteit en blijft dat doen.
Hieronder een samenvatting in hoofdlijnen welke data gerelateerde rollen er mee kunnen werken:
Big Data Analyse:
- Data-analyse op grote schaal: Het verwerken en analyseren van grote datasets met behulp van Apache Spark.
- Realtime data-analyse: Het analyseren van stroomgegevens in real-time voor direct inzicht.
Machine Learning:
- Modeltraining en -evaluatie: Het bouwen, trainen en evalueren van machine learning modellen.
- Modeldeployment: Het inzetten van machine learning modellen voor productieomgevingen.
Data Engineering:
- ELT-processen: Extract, Load, Transform processen voor het verzamelen, transformeren en laden van data van verschillende bronnen naar data lakes en data warehouses.
- Data pipeline automation: Het automatiseren van data pipelines voor continue dataverwerking en analyse.
Data Science:
- Exploratory Data Analysis (EDA): Het verkennen en visualiseren van data om inzichten te verkrijgen.
- Collaborative notebooks: Het gebruik van notebooks (zoals Jupyter Notebooks) voor samenwerking tussen data scientists.
Business Intelligence:
- Dashboards en rapporten: Het creëren van interactieve dashboards en rapporten voor zakelijke inzichten.
- Ad-hoc query’s: Het uitvoeren van ad-hoc query’s om snel antwoorden te krijgen op specifieke zakelijke vragen.
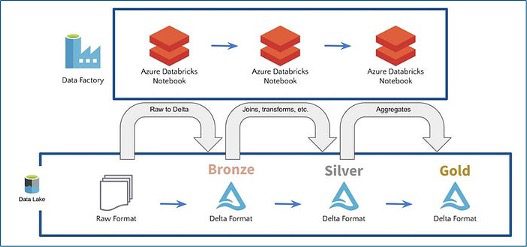
Het verloop van data in Databricks van bron tot dashboard: De Medallion Architecture
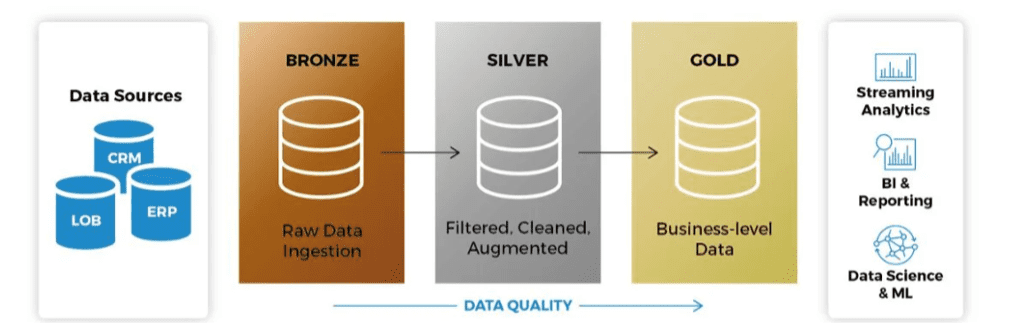
De Medallion Architecture in Databricks helpt bij het organiseren van data door het op te splitsen in drie lagen: bronze, silver, en gold. Elke laag heeft een specifieke rol in het opschonen en verfijnen van data, wat zorgt voor een efficiënte en gestroomlijnde verwerking. Je kan dit ongeveer vergelijken met staging, dwh en presentatielaag vanuit de traditionele datawarehouse principes.
- Bronze: Hier wordt alle ruwe data verzameld uit bijvoorbeeld een database, direct vanuit de bron. Dit is je “single source of truth”, waar alles wordt opgeslagen zonder directe transformaties.
- Silver: In deze laag wordt de data opgeschoond, gevalideerd en verrijkt. Duplicate records worden verwijderd en datasets worden gecombineerd, zodat de data klaar is voor verdere analyse.
- Gold: Dit is de laag waar geoptimaliseerde en geaggregeerde data wordt opgeslagen, klaar voor directe consumptie door BI-tools of machine learning-modellen. Deze datasets zijn geoptimaliseerd voor specifieke business use cases. In deze laag worden ook de dimensionele modellen opgeslagen.
Door data stapsgewijs door deze lagen te laten gaan, creëer je meer controle, verbeter je de datakwaliteit en maak je de datasets geschikt voor verschillende teams en doeleinden.
Delta Lake sluit perfect aan bij deze architectuur, omdat ze het opslaan, transformeren en beheren van data eenvoudig en schaalbaar maken.
Datalakehouse de opvolger van het Data Warehouse
De kern van Databricks is de Databricks Lakehouse, een architectuur die de voordelen van Data Lakes en Data Warehouses combineert.
Dit is een vernieuwing op het traditionele DataWarehouse.
Hieronder zien we de verschillen van een Traditioneel Data Warehouse naar Data Lakehouse.
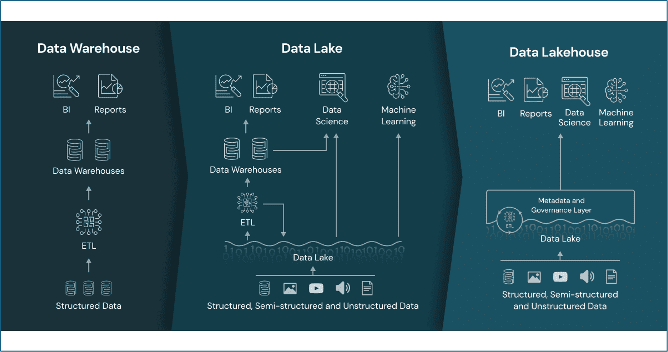
Een datalakehouse in Databricks en een traditioneel datawarehouse hebben beide als doel om data op te slaan, beheren en analyseren, maar er zijn belangrijke verschillen in hun architectuur, functionaliteit en toepassingen.
Flexibiliteit:
- Ondersteunt zowel gestructureerde als ongestructureerde data.
- Schema bij lezen, wat meer flexibiliteit biedt omdat de gegevensstructuur tijdens het lezen kan worden gedefinieerd, er wordt dus flexibel omgegaan met kolomnamen en datatypes.
- Gebruik van open bestandsindelingen zoals Parquet en Delta Lake voor opslag, dit is een ontzettende efficiënte manier van dataopslag.
- Er is qua infrastructuur integratie mogelijk met alle grote cloud providers (AWS/Azure/GCP) waardoor er geen sprake is van vendor lock-in.
Schaalbaar:
- Hoge schaalbaarheid doordat het gebaseerd is op cloud-native architecturen en gedistribueerde opslag en computing.
- Kostenefficiënt doordat het gebruik maakt van commodity hardware en cloud-opslag.
Prestaties:
- Gebruik van Delta Lake in Databricks biedt ACID-transacties en indexing mogelijkheden om query-prestaties te verbeteren.
- Ondersteuning voor geavanceerde analytics en machine learning workloads dankzij geïntegreerde tools en frameworks.
Kosten:
- Meer kostenefficiënt doordat het gebruik maakt van cloud-opslag en gedistribueerde computing.
- Betaling naar gebruiksmodel (pay-as-you-go) wat kosten bespaart bij variërende workloads.
Het Data Lakehouse biedt één enkele bron van waarheid voor alle data binnen een organisatie, ongeacht of het gestructureerd of ongestructureerd is.
Dit maakt het mogelijk om data snel te analyseren en te transformeren, zonder dat het eerst door meerdere systemen moet gaan.
Wil je meer weten over Datalake(house) lees dan ook vooral het blog van mijn Collega Joerie: https://conspect.nl/datawarehouse-vs-datalake-nog-een-fancy-buzz-woord/
Wat is Parquet en wat is de Term ACID
Eerder in deze blog is de term Parquet mogelijk opgevallen. In deze alinea wil ik Parquet even benoemen omdat dit een modern bestandsformat is waar veel voordelen biedt.
Parquet is een open-source kolom-gebaseerd bestandsformaat dat geoptimaliseerd is voor efficiënte opslag en het verwerken van grote hoeveelheden data. Doordat het een kolom-formaat is, biedt Parquet aanzienlijke voordelen als het gaat om het comprimeren van data en het uitvoeren van snelle, geoptimaliseerde query’s. Dit maakt het vooral populair binnen data lakes en big data-omgevingen, waar snelheid en opslagkosten cruciaal zijn. Databricks is uiteraard geschikt om met Parquet datatype te werken.
Hoewel Parquet zeer efficiënt is in opslag en verwerking, heeft het geen ingebouwde mechanismen voor ACID-transacties (Atomicity, Consistency, Isolation, Durability). Dit betekent dat als er iets fout gaat tijdens het schrijven of updaten van data, het best moeilijk is om consistentie en fouttolerantie te garanderen. Hier komt Delta Lake om de hoek kijken. Delta Lake, de technologie achter Databricks, bouwt voort op Parquet en biedt een laag bovenop Parquet-bestanden die ACID-mogelijkheden toevoegt. Dit zorgt voor betrouwbaarheid en transacties op je data, zodat je verzekerd bent van consistente data, zelfs bij crashes of mislukte bewerkingen.
Door deze combinatie van Parquet’s opslag-efficiëntie en Delta Lake’s ACID-functionaliteit krijg je het beste van twee werelden: de snelle verwerking van grote datasets en de betrouwbaarheid van robuuste databeheer met transactieondersteuning.
Is Databricks dan écht overal voor te gebruiken?
Nee, er zijn ook situaties waar Databricks niet ideaal voor is. Een voorbeeld hiervoor is API’s op basis van delta tabellen.
Recent werd ik bij mijn klant benaderd om te kijken of we middels een Delta tabel een API kunnen vullen, de notebook zou dan dagelijks middels allerlei query’s de data ophalen en deze naar de delta tabel wegschrijven.
Wanneer de API dan nieuwe data nodig heeft zou dit geautomatiseerd op een vast tijdstip worden opgehaald uit deze delta tabel.
Na wat onderzoek bleek dit een onhandige oplossing, de hoofdreden hiervoor was kosten.
De flexibiliteit die Databricks heeft is in deze ook een valkuil. Zo kan een Delta Table alleen worden uitgelezen op het moment dat het cluster actief is, nu bepaal je o.a. per startmoment en voor de tijdsduur.
Wanneer een Delta tabel meerdere malen per dag wordt geraadpleegd omdat er verschillende API calls binnenkomen is een Databricks delta tabel niet de juiste oplossing omdat er elke keer het cluster wordt gestart.
In dit geval kunnen we Databricks beter gebruiken om de data weg te schrijven naar een Azure blob storage of een Azure table storage in plaats een Delta lake.
Een ander belangrijk punt is dat Databricks niet altijd de beste keuze is voor situaties met kleine hoeveelheden data of eenvoudige use-cases. Voor zulke scenario’s kan Databricks namelijk overkill zijn vanwege de complexiteit en de overhead die gepaard gaat met het beheren van clusters. Bij kleine volumes of minder complexe workflows kunnen tools Azure Data Factory in combinatie met Azure SQL een eenvoudiger en kostenefficiënter alternatief zijn. Het draait dus om een fit-for-purpose benadering: hoewel Databricks veelzijdig en krachtig is, is het niet altijd de juiste tool voor elk probleem, vooral niet wanneer eenvoud en kostenbeheersing cruciaal zijn.
Strategische voordelen van databricks als cloudoplossing:
Databricks biedt ten opzichte van on premise tools de volgende voordelen:
Schaalbaarheid en flexibiliteit:
Een van de grootste voordelen van Databricks is de mogelijkheid om snel te schalen. Voor organisaties die werken met groeiende datasets, biedt Databricks de flexibiliteit om rekenkracht en opslag eenvoudig op te schalen zonder in te boeten op prestaties. Dit is met name relevant voor bedrijven die in een omgeving opereren waarin gegevensvolumes snel toenemen, zoals e-commerce, gezondheidszorg en financiële dienstverlening.
Kosten-efficiëntie:
Met de opkomst van cloud computing zijn organisaties steeds meer bezig met het optimaliseren van hun IT-uitgaven. Databricks biedt ‘pay-as-you-go’ pricing, wat betekent dat organisaties alleen betalen voor wat ze gebruiken. Dit kan een grote kostenbesparing opleveren ten opzichte van traditionele on-premise oplossingen, die vaak vaste infrastructuurkosten hebben, zelfs wanneer deze niet volledig worden benut.
Uitdagingen van Databricks als cloudoplossing
Zoals elke tooling zijn er ook uitdagingen en/of potentiële gevaren bij een Databricks implementatie, hieronder zijn deze samengevat:
Kostenbeheersing:
Hoewel Databricks kosten-efficiënt kan zijn, is het belangrijk om de kosten goed te monitoren. Ongecontroleerd gebruik van rekenclusters en opslag kan leiden tot onverwacht hoge kosten. Het vraagt om strikte governance en beleid om te zorgen dat resources optimaal worden ingezet en dat teams bewust zijn van hun verbruik.
Adoptie binnen de organisatie:
Het succes van Databricks hangt sterk af van de adoptie binnen de organisatie. Hoewel het een krachtige tool is, vraagt het om een leercurve en veranderende werkmethoden. Het implementeren van Databricks vereist training en de bereidheid van teams om nieuwe tools en processen te omarmen. Het kan een uitdaging zijn om dit op een efficiënte manier binnen de gehele organisatie door te voeren.
Afhankelijkheid van de cloud:
Databricks is sterk afhankelijk van cloudleveranciers zoals Azure, AWS en Google Cloud. Compliance en Datalokaliteit buiten beschouwing gelaten, betekent dit ook dat bedrijven afhankelijk zijn van de cloudleverancier voor uptime en beveiliging.
Conclusie:
Hoewel Databricks veel functionaliteiten biedt, is het niet in alle situaties de ideale oplossing.
Het is een relatief technische oplossing die afwijkt van de traditionele aanpak in Datawarehousing door een meer geïntegreerde en schaalbare benadering van data-management en analyse te bieden.
Zoals eerder verteld is het ook zaak te realiseren dat er binnen cloudplatformen voor elke soort dataverwerking vaak wel een optimale tool is, Databricks is een onderdeel dat meerdere tools vervangt, maar niet alles.
Denk aan het eerdergenoemde voorbeeld van API’s op basis van delta tabellen of dashboards, verder kunnen de kosten en operationele complexiteit soms een uitdaging vormen.
Ook is de kennis nog wat minder wijdverspreid als de traditionele Datawarehouse-oplossingen die al langer gebruikt worden.
Het is natuurlijk altijd belangrijk voor organisaties om de specifieke behoeften en use-cases te evalueren voordat ze voor bepaalde oplossingen zoals Databricks kiezen.
Ook interne kennis is van belang, het vergt een nieuwe manier van werken, die ondanks het ondersteunen van SQL wel wat aanpassingen vergt, verder is python kennis wel nodig en het willen leren van werken met een datalakehouse.
Er is dus technische kennis benodigd om te starten met Databricks omdat het een tool zit waar mensen aan het meer technische kant van het data-vakgebied mee werken.
Benieuwd naar wat Databricks voor jouw organisatie kan betekenen?
Of je nu grote volumes aan data wil verwerken, analyseren of geavanceerde AI-modellen wilt bouwen, met Databricks heb je de tools om jouw datadoelen te bereiken. Start vandaag nog met het ontdekken van de kracht van deze veelzijdige alleskunner en til je dataprojecten naar een hoger niveau. Neem contact op met Conspect via Info@conspect.nl of bel ons op 036-5387292

Martijn van Dongen
Data Engineer @ Conspect